Algumas vezes surge a necessidade de fazermos algum processamento em uma base de dados, como requisições e afins. É muito comum neste momento recebermos um CSV ou até mesmo uma planilha do Excel, ai neste momento devemos escrever um script que processe essa informação. Suponhamos que precisamos atualizar o nome de algum cliente dado seus id’s e nomes, seguindo um arquivo neste modelo:
| |
A abordagem mais simples que eu sigo é iniciar criando uma função primária, que no geral chamo de main e iterar no arquivo CSV usando um DictReader:
| |
Como pode ser visto, na linha 9 abrimos um arquivo utilizando um gerenciador de contexto, que tem a vantagem de fechar o arquivo automaticamente ao sair do escopo do with.
Após isso na linha 10 criamos um DictReader que é um leitor de CSV que tem a vantagem de ao ler o arquivo CSV gerar registros em forma de dicionários, permitindo acessarmos seus campos pela chave do CSV: register[‘id’], por exemplo, ao invés de registro[0] (porém é importante destacar que para isso o arquivo deve possuiir cabeçalho com o nome dos campos ou você deve passar na chamada do DictReader uma lista com os nomes dos campos, vide documentação aqui).
Uma vantagem dessa abordagem é que tudo ocorre utilizando iteradores, que ao invés de carregar todo o arquivo em memória para processa-lo, acessa linha a linha o arquivo faz o processamento individual. Quando executarmos o script já obteremos o seguinte resultado:
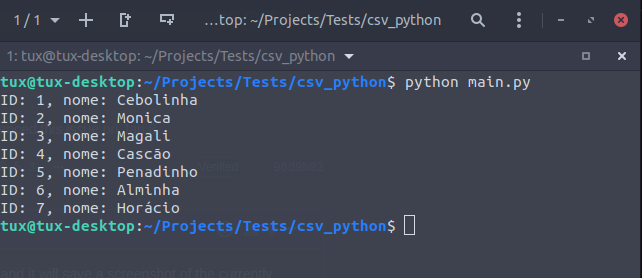 Já com este esqueleto principal montado podemos seguir com a parte de requisição, para isso podemos usar uma biblioteca de requisições como a requests. Basta colocarmos a importação da biblioteca e o código em questão na função process_register:
Já com este esqueleto principal montado podemos seguir com a parte de requisição, para isso podemos usar uma biblioteca de requisições como a requests. Basta colocarmos a importação da biblioteca e o código em questão na função process_register:
| |
Com isso já temos um script básico para fazer requisições em lote, caso o retorno seja um json ao invés de response.text podemos usar um response.json(). Podemos substituir a chamada de uma API para uma atualização em um banco de dados ou até mesmo a geração de outro arquivo, além de melhorias como controle de reprocessamento usando um banco SQLite (que já vem com o drive nativamente no Python) ou melhorar a performance utilizando funções assíncronas e fazer as requisições concorrentemente.