Este post é uma continuação direta do post Lendo arquivos CSV em Python e fazendo requisições - Parte 1
Depois de conseguirmos ler o CSV e conseguirmos fazer requisições em lote, podemos agora iniciar uma primeira otimização, realizar as cotações em paralelo. Para isto usaremos a API assíncrona do Python em conjunto com uma nova biblioteca de requests, a HTTPX.
A primeira coisa que faremos é alterar a biblioteca Python que utilizamos, adaptar a requisição e nosso programa para começar a trabalhar assíncronamente. As alterações são principalmente na definição das funções e também nas mudanças para as chamadas das funções assíncronas que agora precisam do await antes:
Após isso também precisamos rodar o novo main assíncrono através de um EventLoop. Python possui diversos modelos de concorrência e paralelismo, o que usaremos aqui são as corrotinas, que são rotinas que funcionam de maneira cooperativa, isto é, quando uma função chega num ponto onde ela aguardará um determinado tempo ela cede a execução do interpretador para outras atividades. No Python essa concessão ocorrerá em momentos de entrada e saída de dados, como a leitura de um arquivo, acesso a um banco de dados ou, como nosso caso, a requisição de uma API web. Uma explicação simples como funcionam as corrotimas pode ser vista aqui.
"Legal Lucas, mas executei aqui e ainda está executando uma request de cada vez!"
Sim, este é um ponto, mesmo já utilizando a API async do Python, nosso código ainda não está executando as requests concorrentemente. Para isso precisamos preparar as corrotinas, convertendo elas em tarefas (tasks) e executa-las concorrentemente através de uma API oferecida para o Python:
Agora as coisas ficaram bem mais interessantes, quando executamos percebemos que simplesmente é disparado na tela todos as impressões de retorno uma única vez e fora de ordem.
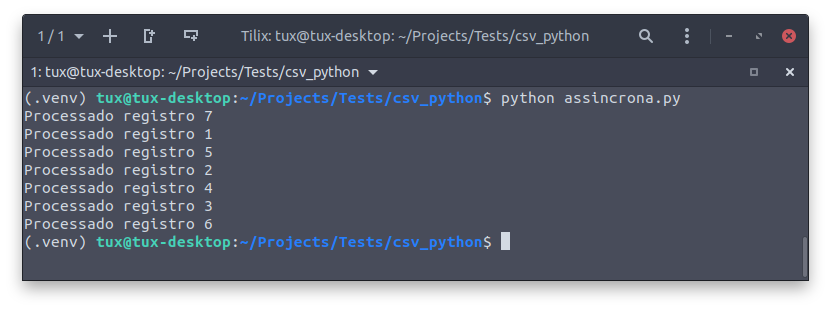
Podemos também fazer uma comparação de tempo de execução da versão síncrona e da versão assíncrona:
Perceba que a diferença de tempo é absurda, sendo 2.17 segundos na versão síncrona contra 0.46 segundos na versão assíncrona. Mas ai você se pergunta: "Por que então não fazemos tudo assíncrono e em paralelo?". Essa é uma pergunta simples com uma resposta difícil, várias coisas entram em jogo quando começamos a realizar operações assíncronas, só vou citar uma delas para inicio de conversa, a memória. Com todas estas operações sendo executadas concorrentemente o computador armazena todos os estados em memória ao mesmo tempo, ao contrário da execução síncrona que executa uma vez, libera memória e vai para o próximo processamento. Existem tópicos sobre essa questão ainda muito mais críticos, como as condições de corrida (racing conditions), mas não é o objetivo aqui se estender neste assunto nesta séries de posts.
Ainda podemos adicionar um controle mais fino desse processamento em
paralelo, como executar em lotes o processamento para não sobrecarregar o
servidor que estamos chamando e nem a nossa máquina. Vamos tentar fazer isso num próximo post, além de alguns últimos acréscimos interessantes.
Nenhum comentário:
Postar um comentário